Zürich, Erfurt, Berlin & Heilbronn
SEO & SEA seit 2008
15-köpfiges Team
Wenn eine Suchmaschine wie Google identischen Content auf verschiedenen Domains findet, ist von Duplicate Content die Rede. Solche doppelten Inhalte können negative Auswirkungen auf Ihre SEO-Massnahmen und auf Ihr Ranking in den Google-Suchergebnissen haben. In diesem Beitrag zeigen wir Ihnen daher, was Duplicate Content ist und wie Sie doppelte Inhalte auf der eigenen Website finden und vermeiden können, um die Wirkung Ihrer SEO-Massnahmen nicht zu behindern.
Der englische Begriff “Duplicate Content” kann mit “doppelter Inhalt” übersetzt werden. Wenn derselbe oder ein sehr ähnlicher Inhalt unter mehreren URL Adressen gefunden wird, versteht man dies als Duplicate Content.
Wann wird von Duplicate Content gesprochen?
Wenn sich Inhalte im Web gleichen, d.h. identische oder ähnliche Textabschnitte auf unterschiedlichen URLs durch Suchmaschinen gefunden werden, spricht man von Duplicate Content.
Es ist wichtig zu wissen, ab wann Google von Duplicate Content ausgeht. Für die Definition als Duplicate Content reicht es aus, wenn einzelne Textpassagen kopiert sind, es muss nicht der gesamte Text sein. Dennoch werden beispielsweise verschiedene Sprachversionen einer Website und Zitate nicht als Duplicate Content gewertet. Zitate sollten Sie dafür aber im Quellcode entsprechend kennzeichnen.
Man unterscheidet zwischen verschiedenen Arten von Duplicate Content. Zunächst gibt es unterschiedliche Abstufungen: Ein Duplikat oder eine Seitendoppelung ist dann der Fall, wenn eine oder mehr Seiten identisch mit einer anderen sind. Diese Übereinstimmung muss nicht hundertprozentig sein, die Seitentitel können sich auch bei identischem Content unterscheiden, und dennoch als Duplikat wahrgenommen werden.
Neben solchen reinen Duplikaten kann es auch sein, dass der Inhalt einer Seite durch eine andere Seite übernommen und mit weiterem Content ergänzt wird. Dieses Problem kann zum Beispiel bei Blogs auftreten, wenn die gleichen Artikel unter mehreren URLs angezeigt werden, wie bei Tag-Seiten und Artikelseiten.
Beispiel: Der Artikel “OnPage SEO” wird auf der Blogseite von seonicals® angezeigt, wenn Sie alle Blogartikel durchsuchen. Ebenso taucht er aber unter einer anderen URL auf, wenn der Filter “SEO” angewendet wurde:
Eine weitere Abstufung ist “Near Duplicate Content”. Hier handelt es sich um das Vorkommen von gleichen Inhalten auf verschiedenen URLs, die zu demselben Thema erstellt sind, aber unterschiedlich aufbereitet und formuliert wurden. Beispielsweise gibt es im Netz viele ähnliche Artikel zum Thema “Duplicate Content”, deren inhaltliche Aspekte zwar ähnlich sind, aber dennoch anders aufbereitet und formuliert wurden.
Unique Content ist natürlich die erste Wahl, wenn es um Inhalte geht. Er bezeichnet einen individuellen, originellen und qualitativen Web-Content, der nur unter einer URL verfügbar ist. Durch solche Inhalte können Sie Ihren Usern einen besonderen Mehrwert bieten und nachhaltig in der Suchmaschinenoptimierung erfolgreich sein.

Duplicate Content kann nicht nur verschiedene Abstufungen haben und unterschiedliche Ursachen, sondern aufgrund der Ursachen auch in internen und externen Duplicate Content unterschieden werden:
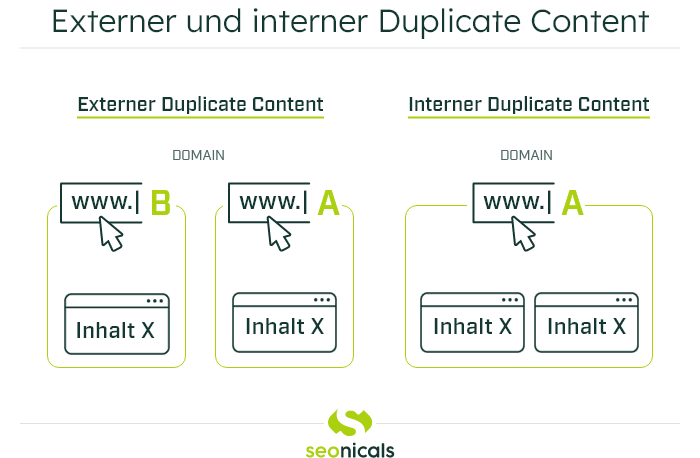
Bei der Definition von Duplicate Content muss zwischen internem und externem Duplicate Content unterschieden werden.
Ausserdem unterscheidet man, ob Duplicate Content böswillig oder nicht böswillig eingesetzt wird. Im Folgenden erklären wir Ihnen die verschiedenen Arten von Duplicate Content genauer.
Wenn identische Inhalte auf zwei oder mehr voneinander unabhängigen Domains zu finden sind, spricht man von externem Duplicate Content (external duplicate content). Externer Duplicate Content ist ein domainübergreifendes Problem, er betrifft demnach nicht allein Ihre Domain, sondern auch die mindestens einer weiteren Partei.
Kopieren Sie beispielsweise Inhalte anderer Websites auf Ihre eigene, spricht man von externem Duplicate Content. Wenn Sie aber selbst mehrere Domain-Varianten besitzen und die Inhalte Ihrer eigenen Website über mehrere Domainnamen erreichbar sind, sollten Sie diese auf eine Hauptdomain weiterleiten. Tun Sie das nicht, sieht Google diese Seiten als unterschiedliche Domains an, die denselben Inhalt bieten und das kann in den Google-Rankings zu Problemen führen.
Externer Duplicate Content kann sein:
Um sich und Ihre Website vor dem Diebstahl Ihrer Inhalte zu schützen, können Sie einen Kopierschutz einrichten. Durch Programmierung mit CSS und Javascript können Sie Ihren Text so anlegen, dass er bei dem Rechtsklick auf die Maus nicht kopierbar ist. Auch auf WordPress ist für den Schutz Ihres Contents ein Plugin verfügbar. Ein Nachteil dieser Funktion ist aber, dass die Nutzererfahrung unter solchen Schutzvorrichtungen leiden kann. User, die Ihre Informationen für eigene Projekte, wie Arbeit, Schule oder Uni benötigen, haben keinen direkten Zugriff auf Ihren Content und verlassen Ihre Website sehr wahrscheinlich schnell wieder, auch wenn die Inhalte gut aufbereitet sind.
Eine andere Möglichkeit, gegen Content-Diebstahl vorzugehen, ist ein Hinweis auf das Urheberrecht, beispielsweise im Footer oder an der Seite. Dort legen Sie verständlich fest, was mit Ihrem Content geschehen darf und was nicht und weisen auf rechtliche Konsequenzen hin. Wenn Sie diesen Hinweis allerdings auf jeder URL hinterlegen, kommt es zu internem Duplicate Content. Achten Sie also unbedingt auf technische Anpassungen.

Sollte es dennoch zu Content-Diebstahl auf Ihrer Webseite kommen, haben Sie verschiedene Möglichkeiten: Sie können den Besitzer der Website kontaktieren, um ihn auf die Urheberrechtsverletzung hinzuweisen. Nennen Sie Beispiele und Argumente gegen sein Handeln und bitten Sie um Entfernung der Duplikate. Ist dieser Weg nicht erfolgreich, sollten Sie einen Rechtsanwalt kontaktieren. Dieser klärt Sie über Ihre Möglichkeiten und Erfolgsaussichten auf.
Werden innerhalb Ihrer eigenen Domain identische Inhalte festgestellt, wird dies als interner Duplicate Content definiert. Hierbei sind nicht nur identische Inhalte oder Passagen, sondern auch gleichbleibende Texte in der Seitenleiste der URL betroffen. Häufig kommt es beispielsweise bei Online-Shops dazu, dass durch Filter-Parameter dieselben Produkte unter verschiedenen Kategorien oder Filtern aufrufbar sind.
Interner Duplicate Content kann auch durch technische Fehler entstehen, für die entsprechende Anpassungen vorgenommen werden können, um diese Probleme zu vermeiden.
Die Ursachen von identischen oder sehr ähnlichen Inhalten auf verschiedenen internen URLs sind vielfältig:
Mit und ohne “www.”:
Doppelte Inhalte können entstehen, weil Ihre Webseite sowohl mit als auch ohne die Subdomain “www.” erreichbar ist.
Übertragungsprotokoll:
Doppelte Inhalte können entstehen, weil Ihre Webseite ebenso mit dem Übertragungsprotokoll “http” wie auch über “https” erreichbar ist.
Slashs:
Schrägstriche am Ende der Domain sollten vermieden werden, da sie ein Verzeichnis suggerieren:
https://beispieldomain.de/ oder https://beispieldomain.de
Gross-und Kleinschreibung in der URL:
Generell sollten Sie sich auf Kleinschreibung festlegen:
https://BeispielDomain.de oder https://beispieldomain.de
Index.html:
Doppelte Inhalte, weil Ihre Startseite mit und ohne “index.html” aufgerufen werden kann:
URL-Parameter:
Doppelte Inhalte, weil Ihre Inhalte mit verschiedenen URL-Parametern aufrufbar sind, wie bei unterschiedlichen Sortierungen in Online-Shops (hier: Preis aufsteigend; absteigend):
https://beispieldomain.de/produkt/?p=1&o=3
https://beispieldomain.de/produkt/?p=1&o=4
Domainwechsel:
Sie haben doppelte Inhalte auf Ihren Websites, weil Sie Ihre Domain gewechselt haben und die gleichen Inhalte auf der neuen Domain verwenden.
Besitz mehrerer Domains:
Sie besitzen und betreiben verschiedene Domainnamen, um eine Besetzung dieser Domains durch Dritte zu verhindern. Diese bespielen Sie mit den gleichen Inhalten.
Kategorie- und Tagseiten:
Beiträge sind über verschiedene URLs verfügbar, wenn beispielsweise Filter angewendet werden:
https://beispieldomain.de/blog/?p_post_filter=thema
Paginierung (Seitennummerierung):
Dieselben Informationen sind auf verschiedenen Seiten eines Online-Shops verfügbar:
https://beispieldomain.de/produkt/?p=1
https://beispieldomain.de/produkt/?p=2
Druckversionen von Webseiten:
Sie besitzen für den Druck optimierte Seiten, die auf einige wesentliche inhaltliche Bestandteile reduziert wurden.
Länderspezifische Domains:
Verschiedene Sprachversionen einer Seite führen zwar nicht zu Duplicate Content, aber verschiedene URLs für Länder, in denen dieselbe Sprache gesprochen wird, können problematisch sein. Deutschsprachige Länder wie Deutschland, Österreich und die Schweiz beispielsweise teilen sich eine Sprache, benötigen aber wegen Steuersätzen und Versandkosten unterschiedliche URLs.
Mobile Versionen einer Website:
Sie besitzen Webseiten, die auf kleinere Bildschirmgrössen angepasst sind, aber die gleichen Inhalte haben:
Verwendung identischer Inhalte von externen Seiten:
beispielsweise die direkte Übernahme von Produktbeschreibungen vom Hersteller oder ähnliche Produktbeschreibungen im eigenen Online-Shop:
Interne Suche:
Die Ergebnisse der internen Suche auf Ihrer Website haben ebenfalls andere URLs, aber denselben Inhalt. Diese sollten von Google nicht indexiert werden.
Seitenleisten und Footer:
Hier finden Sie allgemeine Informationen wie Seitenbeschreibungen, Adressen, Impressum und andere Kontaktdaten. Diese sind über fast alle URLs aufrufbar.
Meist verbindet Google Duplicate Content nicht mit einer Täuschungsabsicht. Es wird bei Duplicate Content nicht immer davon ausgegangen, dass Inhalte böswillig kopiert werden, um beispielsweise das eigene Ranking in den Suchergebnissen zu manipulieren.
Nicht böswilliger Duplicate Content kommt beispielsweise vor
Wird Content auf manipulative Art kopiert (Scraping/ Suchmaschinen-Spam), um Klicks und Traffic zu generieren, spricht man von böswilligem Duplicate Content.
Spamming zielt darauf ab, mehr Website-Besucher zu generieren und damit höhere Werbeeinnahmen zu erreichen. Diese Websites werden jedoch im Ranking niedriger eingestuft oder durch Google Penalties vollständig aus dem Index entfernt.
Durch Duplicate Content kann es auf Ihrer Website zu Problemen kommen, auch wenn Ihre Inhalte ansonsten gut aufgearbeitet sind. Wenn Google solche identischen oder sehr ähnliche Inhalte findet, werden diese nämlich nicht mehr als einzigartig beurteilt. Die Einzigartigkeit Ihrer Website und der Inhalt darauf ist aber ausschlaggebend für eine positive Bewertung durch Suchmaschinen wie Google. Duplicate Content kann dementsprechend negative Auswirkungen auf Ihre Website haben. Mögliche Folgen sind schlechtere Rankings in den Google Suchergebnissen und ausbleibender Erfolg auf dem digitalen Markt.
Sie sollten beim Content Ihrer Website am besten auf einmalige und einzigartige Texte setzen. Diese verhindern nicht nur Probleme durch doppelten Content, sondern sorgen auch für nachhaltigen Erfolg in den Suchmaschinen und heben Sie inhaltlich von der Konkurrenz ab. Bei doppelten Inhalten fällt es Suchmaschinen wie Google nämlich schwer, zu entscheiden, welche Seite relevanter ist als die andere und daher in den Suchergebnissen angezeigt werden soll.
Wie Sie selbst professionelle Website-Texte erstellen, lernen Sie bei uns. Gerne stehen wir Ihnen auch mit unserem erfahrenen Redaktionsteam zur Seite, das Ihre Website mit einzigartigem und suchmaschinenoptimiertem Inhalt füllt.
Auch beim Thema Backlinks entstehen Probleme durch Duplicate Content. Wenn Sie auf Ihrer Website doppelte Inhalte haben, kann es sein, dass andere Websiten nicht auf die von Ihnen gewünschte URL verweisen. Sie können dadurch wertvolle Backlinks verlieren. Gleichzeitig ist es möglich, dass zwar auf beide Websites verwiesen wird, aber dafür nur selten, sodass keine der URLs eine starke Backlink-Struktur hat.
Wie Google Duplicate Content findet und weshalb Ihnen das Kopieren von Content aus SEO-Sicht nicht zu empfehlen ist, erklären wir im Folgenden.
Google setzt einen speziellen Algorithmus ein, um Duplicate Content zu erkennen. Das genaue Vorgehen von Google bleibt aber Betriebsgeheimnis. Möglich ist, dass Google nach dem Shingle Algorithmus vorgeht, der oft genutzt wird, um Duplicate Content zu finden. Dabei wird der zu untersuchende Text in einzelne Shingles (Schindeln) aufgeteilt, die dann verglichen werden. So vergleicht der Shingle Algorithmus einzelne Wortgruppen miteinander. Shingles sind dabei sich überschneidende Wortgruppen, die immer aus einer vorher festgelegten Wortzahl bestehen.
Als Beispiel legen wir die Wortzahl drei fest und den letzten Satz:
A: “Shingles sind dabei sich überschneidende Wortgruppen, die… ”
und den Satz:
B: “Wortgruppen werden in sich überschneidende Shingles aufgeteilt, die..”
A:
Shingle 1: Shingles, sind, dabei
Shingle 2: sind, dabei, sich
Shingle 3: dabei, sich, überschneidende
Shingle 4: sich, überschneidende, Wortgruppen
Shingle 5: überschneidende, Wortgruppen, die
…
B:
Shingle 1: Wortgruppen, werden, in
Shingle 2: werden, in, sich
Shingle 3: in, sich, überschneidende
Shingle 4: sich, überschneidende, Shingles
Shingle 5: überschneidende, Shingles, aufgeteilt
…
Die Länge kann variiert werden, aber je kleiner die Wortgruppen sind, desto besser lässt sich Duplicate Content finden. Bei zu kleinen Wortgruppen werden jedoch sehr viele Texte als doppelter oder kopierter Inhalt angesehen, obwohl das gar nicht der Fall ist.
Um durch Shingles festzustellen, ob sich zwei Texte ähneln, werden die Schnittmenge und die Vereinigungsmenge der beiden in Shingles aufgeteilten Texte gebildet. Diese werden dann durcheinander geteilt, um einen Prozentsatz zu berechnen:
Bei den Beispielsätzen unterscheidet sich kein Shingle, somit steht im Zähler eine Null und es ergibt sich eine Überschneidung des Inhalts von 0%. Dieses Ergebnis würde bei kleineren Shingles anders aussehen.
Ein einfacher Algorithmus ist die PHP similar text() -Funktion. Diese berechnet die Ähnlichkeit von zwei Strings. Ein String ist dabei eine Folge von Zeichen von variabler Länge. Das Ergebnis des Vergleiches ist eine Prozentzahl.
Beispiel:
<?php
echo similar_text("string1: Shingles sind dabei sich überschneidende Wortgruppen, die”,”string2:Wortgruppen werden in sich überschneidende Shingles aufgeteilt, die");
?>
Hat Google nach dem Crawlen und der Indexierung gleiche oder ähnliche Inhalte festgestellt, versucht die Suchmaschine herauszufinden, ob es sich um notwendige Duplizierungen handelt oder um Spam. Notwendige Duplizierungen wie beispielsweise sich wiederholende Angaben im Footer wirken sich nicht negativ auf Ihr Ranking aus. Bei Spam-Content verlieren die Seiten jedoch an Relevanz und erzielen keine Rankings mehr. Wenn Google vermutet, dass regelmässig bewusst doppelte Inhalte publiziert werden, kann es zu einer Abstrafung kommen.
Doppelte Inhalte behindern Google darin, für die User das bestmögliche Ergebnis anzuzeigen.
Die Suchmaschine legt grossen Wert auf Einzigartigkeit und eine positive Nutzererfahrung. Um die Nutzer durch doppelte Inhalte nicht zu verwirren und eine negative Erfahrung zu riskieren, muss Duplicate Content herausgefiltert werden. Damit Ihre Webseite als sinnvoll angesehen und positiv bewertet wird, sollte Ihr Content deshalb einmalige Inhalte mit Mehrwert bieten. Nur so kann sie bei Google langfristig erfolgreich sein.

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Google orientiert sich an Indikatoren wie Alter, Qualität und Relevanz des Contents, um Content, der dupliziert oder sehr ähnlich ist, einzuschätzen und die vertrauenswürdigste Quelle höher für ein Keyword zu ranken. Die Suchmaschine ist darauf ausgelegt, in den Suchergebnissen generell nur die Ergebnisse für einen Suchbegriff anzuzeigen, die unterschiedliche und jeweils einzigartige Informationen bieten können. Duplizierte Inhalte ranken also schlechter oder werden erst gar nicht in den Suchergebnissen angezeigt.
Wenn der Google-Suchalgorithmus mehrere URLs mit ähnlichen oder identischen Inhalten indexiert, ist es schwer, daraus die thematische Relevanz der Seiten für die Suchanfrage zu identifizieren. Insbesondere bei internem Near Duplicate Content kann es passieren, dass mehrere URLs bei einer Suchanfrage ranken. Bei dieser sogenannten Keyword-Kannibalisierung ranken für dieselben Keywords zwei URLs, was schlecht für das Ranking in der Suchmaschine ist. Der Google Crawler kann keine eindeutige URL für die Suchanfrage identifizieren. Die Folge ist, dass Google in den Suchergebnissen dann die für Sie falsche URL ranken lassen kann, was sich schlecht auf die User-Erfahrung auswirkt und auch für Sie keinen Vorteil bringt.
Wenn es Seiten gibt, die über verschiedene URLs erreichbar sind oder verschiedene URLs den gleichen Inhalt haben, deutet Google dies als Duplicate Content. Bei diesem Problem wählt Google eine der URLs als kanonische URL aus und crawlt sie anschliessend. Die anderen, ähnlichen URLs werden von Google als dupliziert angesehen und demnach nicht gecrawlt.
Duplizierte Inhalte sind eindeutig ein Problem, denn sie sind nicht die originalen Inhalte. Das hat zur Folge, dass Google nicht erkennt, welche Seite den relevantesten Content für die vom User gestellte Suchanfrage bietet. Duplicate Content kann sich deshalb durch Schwankungen in den SERPs (Search Engine Result Page) niederschlagen. Die angezeigten URLs in den Suchergebnissen können wechseln und den User verwirren. Um dem entgegenzuwirken, versucht Google hier, selbst Duplicate Content zu identifizieren und herauszufinden, welcher Content relevanter für die Suchanfrage des Users ist. Das Ergebnis erscheint dann in den SERPs.
Bei der Indexierung der Inhalte versucht Google, die bessere und relevantere Version der doppelten Inhalte zu finden und diese zu indexieren. In einigen Fällen muss Google annehmen, dass durch duplizierten Content das Ranking manipuliert werden oder dass die User getäuscht werden sollen. In diesen Fällen muss Google Korrekturen am Index und am Ranking der Website vornehmen. So kann es passieren, dass diejenige Website, die duplizierte Inhalte verwendet, schlechter in den Suchergebnissen rankt oder sogar aus dem Google-Index entfernt wird. Duplicate Content kann also durchaus dazu führen, dass Sie mit Ihren Inhalten nicht mehr in den Suchergebnissen auftauchen, denn wenn User identischen Inhalt in unterschiedlichen Suchergebnissen finden, beeinträchtigt dies ihre Nutzererfahrung und ihr Vertrauen in Ihre Webseite.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Ist Ihr Webseiteninhalt nicht der originale Inhalt, sondern dupliziert, wird er in der Regel gar nicht erst gute Google Rankings erzielen. Identifizierter Duplicate Content wird von Google herausgefiltert und erst auf Wunsch des Users angezeigt.
In den meisten Fällen ahndet Google doppelte Inhalte nicht mit einem Penalty (Abstrafung). Google Penalties können Ihre Ranking Position verschlechtern und dazu führen, dass Ihr Sichtbarkeitsindex einbricht. Für internen doppelten Content gibt es keine Penalties. Bei einigen Fällen des externen Duplicate Content spricht Google hingegen Penalties aus. So zum Beispiel bei Domains, die ausschliesslich aus gestohlenem Content bestehen oder bei Seiten, die Inhalte von anderen Seiten automatisiert umschreiben oder übersetzen.
Bei den meisten Fällen von Duplicate Content spricht Google keine Penalty aus. Bei einigen einzelnen fällen spricht Google jedoch sehr wohl Penalties aus:
Diese Penalties äussern sich darin, dass entweder der Sichtbarkeitsindex einbricht oder sich Ihre Ranking Positionen massiv verändern.
Es gibt einige Möglichkeiten, durch die Sie Duplicate Content ausfindig machen können. Eine einfache wäre zum Beispiel, dass Sie direkt in der Google-Suche prägnante Textabschnitte bestimmter Inhalte einfügen, um nach diesen zu suchen. Wenn Sie diese in Anführungszeichen setzen und mehr als einen Treffer erzielen, liegt Duplicate-Content vor.
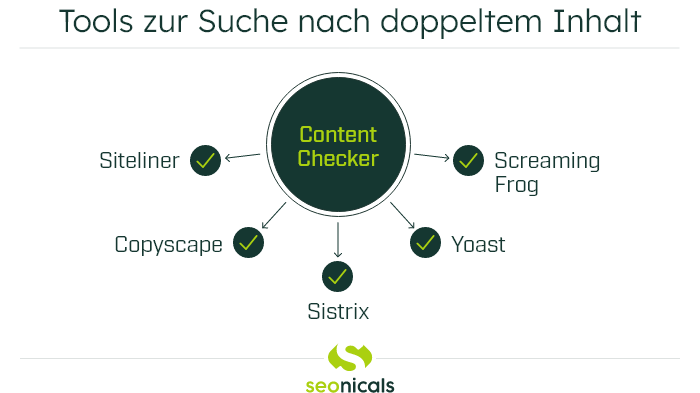
Um den eigenen Inhalt zu prüfen, gibt es verschiedene Möglichkeiten. Kostenlose Duplicate Content Check Tools sind zum Beispiel eine gute Möglichkeit. Diese Tools identifizieren allerdings auch sehr kleine Textausschnitte, die in der Regel kein Problem darstellen. Sie müssen also nach dem Check genau kontrollieren, welche doppelten Inhalte Ihnen Probleme machen können.
Gute Tools, um Ihre Website nach Duplicate Content zu durchsuchen, sind Content Checker wie Siteliner, Copyscape, Screaming Frog, Yoast und Sistrix.
Ein Finder für doppelte Inhalte kann auch die Google-Suche selbst sein. Geben Sie dafür Ihren zu testenden Text bzw. Textabschnitt in Anführungszeichen in die Google Suchleiste ein und lassen Sie sich die Ergebnisse anzeigen.
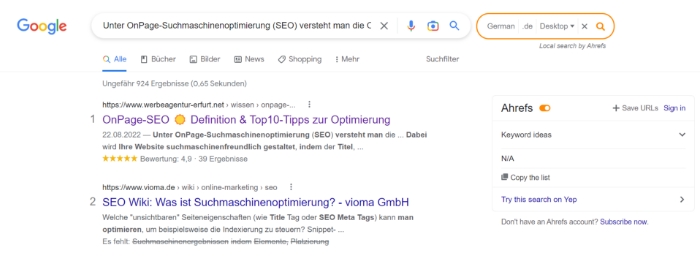
Wenn nur ein Suchergebnis angezeigt wird, ist Ihr Content einzigartig. Gibt es jedoch weitere Suchergebnisse, hat jemand Ihren Content dupliziert oder Sie selbst haben Duplicate Content produziert.
Um internen Duplicate Content, also doppelte Inhalte auf Ihrer eigenen Seite zu identifizieren, können Sie das kostenlose Tool Siteliner verwenden. Es gibt Ihnen einen umfangreichen Bericht, mit dem Sie dann die betroffenen doppelten Inhalte überprüfen können. Bei der kostenlosen Version von Siteliner beträgt das Scan Limit 250 Seiten. Die Anmeldung bei Siteliner Premium 25,000 ist zwar kostenlos, aber jede gescannte Seite kostet 1 ct. 25,000 Seiten zu scannen würde somit 250 € kosten.
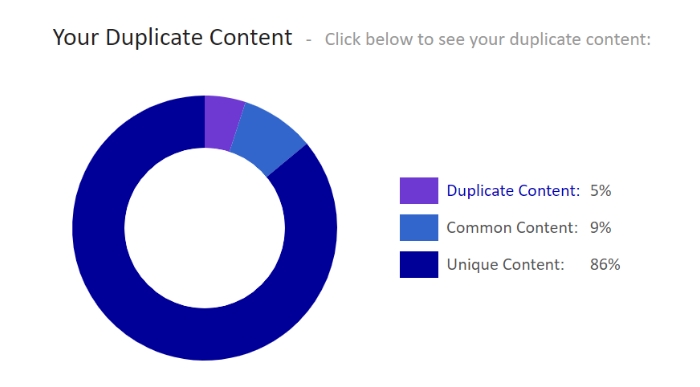
Wie viel Duplicate Content auf Ihrer Seite existiert, wird Ihnen in Prozent angegeben, ebenso wie viel Prozent Ihrer Website aus Common oder Unique Content besteht.
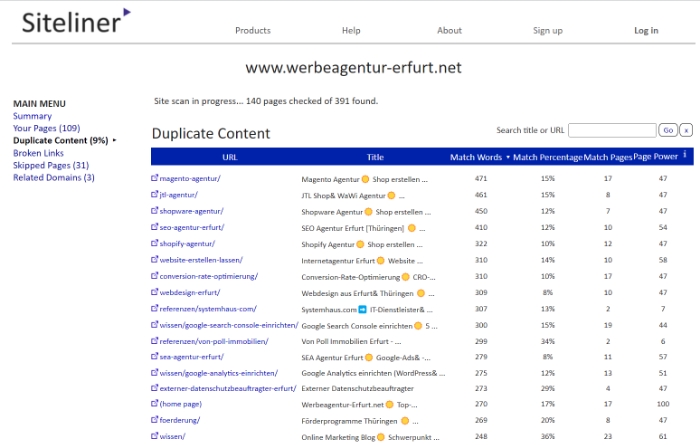
Ebenfalls sehen Sie ausführlich aufgelistet, welche URLs von doppelten Inhalten betroffen sind, wie viele Wörter auf der jeweiligen Seite betroffen sind und mit wie vielen Seiten sich dieser Content überschneidet.
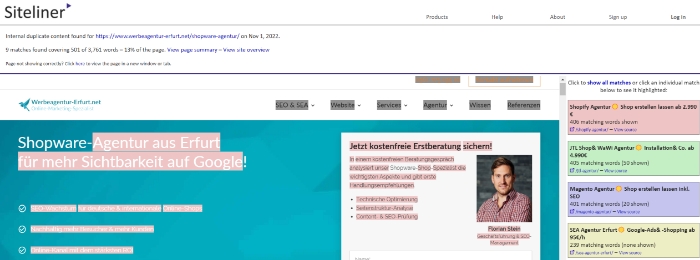
Wenn Sie auf die betroffenen URLs navigieren, sehen Sie durch Siteliner auch markiert, welche Wörter betroffen sind und auf mehreren Seiten auftauchen.
Das kostenlose Tool Copyscape unterstützt Sie dabei, externen Duplicate Content im Netz zu finden. Hierzu können Sie beispielsweise die URL zu einem Ihrer Blogeinträge eingeben und durch das Tool nach Duplikaten suchen.
Zur Veranschaulichung haben wir den Wikipedia Artikel zum Thema Duplicate Content angegeben:
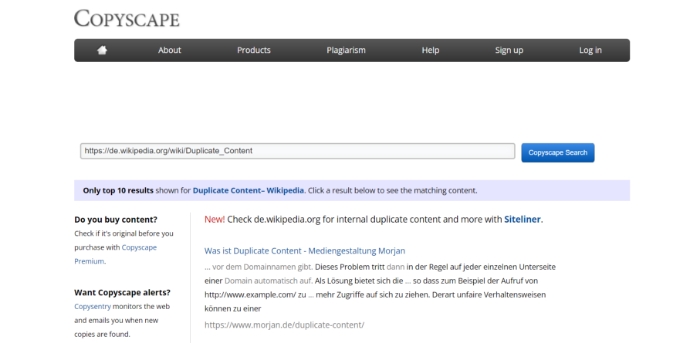
Anschliessend können Sie die betroffenen Seiten aufrufen und die genauen Textpassagen sehen, die dupliziert wurden:
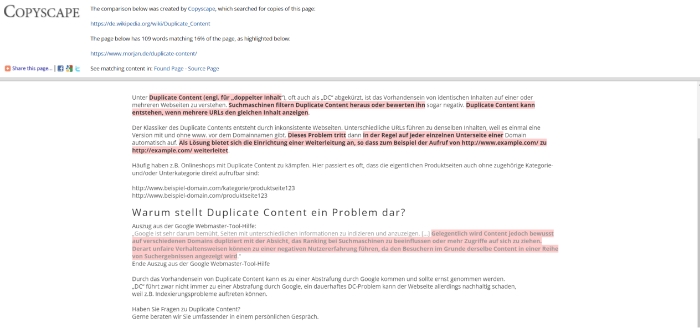
Das Tool selbst ist in seiner einfachen Version kostenlos, es gibt aber eine Premium Version, bei der Sie mehr Möglichkeiten haben, Ihre Website und Inhalte nach Duplicate Content zu durchsuchen. Die Premium Version erlaubt es Ihnen zum Beispiel, auch Ihre pdf-Dokumente zu durchsuchen, ebenso wie Ihre gesamte Website. Die Kosten für die Copyscape Premium Version belaufen sich auf 3 ct pro Suche für Textabschnitte von bis zu 200 Wörtern, und zusätzlich 1 ct je weiterer 100 Wörter.
Das Tool Sistrix überprüft automatisch, ob Inhalte Ihrer Texte bereits in identischer oder ähnlicher Form im Internet aufrufbar sind. So können Sie Duplicate Content leicht vermeiden. Das Tool ist kostenpflichtig und in vier verschiedenen Kategorien erhältlich. Es gibt aber auch die Möglichkeit einer 14-tägigen Testversion.

Mit Sistrix können Sie die Individualität Ihres Contents überprüfen und Plagiate im Web entdecken. Ebenfalls können Sie analysieren, ob Probleme durch Duplicate Content auftreten, beispielsweise durch den Sichtbarkeitsindex, mit dem Sie die Google-Suchergebnisse durchsuchen können. Sie sehen auch, ob auf Ihrer Website ähnliche Inhalte über mehrere URLs erreichbar sind und können somit an diesen Stellen technische Anpassungen vollziehen. Inhalte, die doppelt auf Ihrer Website sind, stellt Sistrix detailliert für jede URL dar.
In Content Management Systemen kommt es leicht zu internem und nicht böswilligem Duplicate Content. So können Beiträge in der Übersicht angezeigt werden, die ebenfalls durch eine andere URL bei Kategorien oder Filtern auftauchen. Wenn Ihre Inhalte über mehrere URLs erreichbar sind, können Sie WordPress so konfigurieren, dass nur die relevanteste Seite in den Google Suchergebnissen angezeigt wird. Für dieses Problem ist das WordPress Plugin “Yoast SEO” nützlich.
Das Plugin kann im WordPress Backend unter “SEO” aufgerufen werden. Eine Tour durch die Möglichkeiten dieses Plugins gibt Ihnen Yoast:
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Mit diesem SEO-Tool können Sie durch einen “noindex” Befehl bestimmte Seiten für den Suchmaschinenindex sperren. Sie selbst entscheiden, welche nicht relevanten Seiten in den Suchergebnissen nicht ausgespielt werden, wie zum Beispiel Inhalte, die über andere URLs erreichbar sind. Das verhindert, dass Google diese Seiten als Duplicate Content einstuft und zeigt in den SERPs nur die Blogartikel an, die auf ein bestimmtes Keyword hin optimiert sind.
Das Tool gibt es in einer kostenlosen und einer zahlungspflichtigen Version. Die zahlungspflichtige Version für 99 €/ Jahr bietet Ihnen jedoch viele Vorteile, wie SEO Training, automatische 404-Seiten und umfangreichere Analysen Ihrer Inhalte.
Das Tool “Screaming Frog SEO Spider” kann für Ihre Website exakte Duplikate und ebenfalls ähnlichen Content finden. Hierfür wählen Sie im Menü “Konfiguration” aus, anschliessend “Inhalt” und zuletzt “Duplikate”. Die Ähnlichkeitsbestimmung kann angepasst werden, denn die SEO Spider identifiziert Nahduplikate voreingestellt bis zu einer Schwelle von 90%.
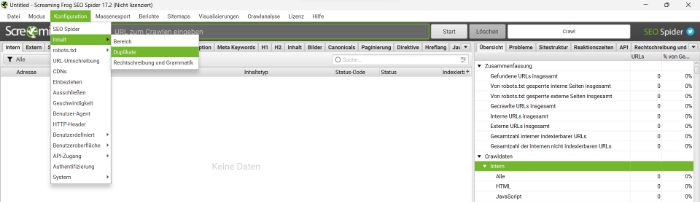
In der kostenlosen Version können Sie über die Übersicht auf der rechten Seite die Prozentzahl an exakten Duplikaten sehen. Nahduplikate werden Ihnen nur dann angezeigt, wenn Sie eine SEO-Spider-Lizenz erwerben.

Für eine zahlungspflichtige Version sprechen die Möglichkeit des unbegrenzten Crawl Limits und des Bestimmens von Nahduplikaten. Natürlich gibt es noch eine Vielzahl weiterer nützlicher Features.
Zum Crawlen müssen Sie über das Menü “Konfiguration”, “Inhalt” und “Bereich” auswählen und den Inhalt für die Analyse definieren. Hier können Sie beispielsweise nav & footer-Tags ausschliessen.
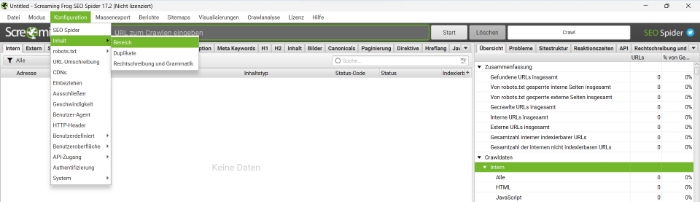
Jetzt können Sie die gewünschte Website crawlen. Fügen Sie dazu einfach unter dem Menü eine URL ein und klicken “Start”.
Wenn Sie durch das Tab “Inhalte” navigieren, können Sie aus zwei Filtern bezüglich Duplicate Content wählen. Danach führen Sie die Crawlanalyse durch, um herauszufinden, welche Daten dupliziert wurden. Unter dem Tab “Crawlanalyse” sollten Sie sicherstellen, dass beim “Konfigurieren” auch die Option “Nahduplikate” ausgewählt ist.

Sie sollten nun den Inhalt in den Spalten “Engste Ähnlichkeitsübereinstimmung” und “Anzahl Nahduplikate” sehen können. Hier können Sie sich den gesamten Prozess der Duplikats-Analyse in der SEO Spider nochmal ansehen:
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Ohne die Absicht doppelte Inhalte zu produzieren, entstehen bei Content Management Systemen wie WordPress und Typo3 viele solcher Dopplungen automatisch. Wenn Sie in WordPress oder Typo3 einen Beitrag erstellen, wird der Text vom System an mehreren Stellen ausgegeben, denn jeder Beitrag erscheint einerseits als eigene Unterseite Ihres Blogs und auch auf der allgemeinen Übersichtsseite aller Blogartikel. Auf dieser Übersichtsseite können Sie je nach Wunsch den gesamten Beitrag anzeigen lassen oder nur einen Textanriss ausspielen.
Auf dieser Übersichtsseite können Sie auch Kategorien oder Schlagwörter auswählen, die dann über eine weitere URL die gefilterten Beiträge mit Textanriss zeigen. Auch auf Archivseiten werden alle Beiträge eines Monats oder eines Autors angezeigt, ebenfalls mit Textanriss. Dies sind Stellen, wo durch ein Content Management System das Problem des Duplicate Content entsteht.
Google kann und wird diese mehrfach vorhandenen Texte/ Textabschnitte als Duplicate Content einstufen. Ebenso ist es möglich, dass Google bei einer Suchanfrage Ihrer User nicht die passende Unterseite ausspielt, sondern stattdessen die Übersichtsseite oder Archivseite Ihres Blogs, die eigentlich gar nicht angezeigt werden soll. Das können Sie durch technische Anpassungen umgehen und so sicherstellen, dass den Usern nur die Ergebnisseiten angezeigt werden, die auch zu Ihren Suchanfragen passen.
Insbesondere beim Schreiben kann es zu Duplicate Content kommen. Übernehmen Sie Passagen oder Zitate aus anderen Artikeln in Ihren eigenen Beitrag, müssen Sie diese Abschnitte unbedingt entsprechend kennzeichnen. Am besten ist es natürlich immer, eigenen Content zu erstellen oder gegebenenfalls Textpassagen soweit umzuformulieren, dass sie nicht mehr als übernommener Inhalt gewertet werden können.
Expertentipp:
Bei WordPress sind Unterseiten der Blogstartseite, Tags (Schlagworte), Kategorien und Anhangseiten anfällig für doppelte Inhalte. Daher sollten Sie bei der Verwendung von Schlagworten und Kategorien aufpassen und diese so sparsam wie möglich verwenden.
WordPress und Typo3 sind Content Management Systeme, bei denen leicht Probleme durch Duplicate Content auftreten können. Um dies zu vermeiden, kann Ihnen in WordPress das Plugin “Yoast SEO” helfen. Durch einen “noindex” Befehl können Seiten wie Archiv- oder Filter-Seiten für den Google Index gesperrt werden. Diese werden nicht indexiert und somit auch nicht als Doppelter Content gewertet.
Bei Shopware Systemen wie Shopify gibt es häufig Probleme mit Duplicate Content. Artikel im E-Commerce haben oft ähnliche oder gleiche Produktbeschreibungen, die man unter verschiedenen URLs findet. Das kann beispielsweise durch Kategorisierung entstehen: Produkte passen in mehrere Kategorien und werden somit unter verschiedenen URLs gefunden. Shops können auch ähnliche Artikel vertreiben, deren Beschreibungen eng beieinander liegen. Google kann in diesen Fällen nicht immer feststellen, dass es sich um unterschiedliche Artikel handelt und wertet deren Beschreibungen als doppelten Content. Um dieses Problem zu umgehen, sollten Sie bestimmen, welche URL von Google gefunden werden soll und alle anderen Varianten der URL mit einem Canonical-Tag versehen.

Eine andere Problematik, mit der sich international agierende Online-Shops konfrontiert sehen, wird durch verschiedene Länderversionen der Website hervorgerufen: Dabei können identische Inhalte für gleichsprachige Länder, beispielsweise Deutschland und Österreich, unter unterschiedlichen URL-Formaten gefunden werden. Hier hilft eine Hreflang-Anmerkung, die die jeweilige geographische Ausrichtung der Website kennzeichnet.
SEO-Strategie für Online-Shops
Wenn auf Ihrer Webseite ein Problem mit Duplicate Content besteht, können Sie dieses durch verschiedene technische Anpassungen beheben:
Ein Canonical-Tag hilft vor allem bei internem Duplicate Content. Wenn Google nicht durch einen Tag mitgeteilt wird, welche URL kanonisch ist, crawled die Suchmaschine im ungünstigsten Fall die falsche URL und zeigt diese dann in den Suchergebnissen an. Unter einer kanonischen URL versteht man die URL, die von mehreren duplizierten Versionen, als die repräsentativste angesehen wird. Mit dem Canonical-Tag können Sie Google also auf die von Ihnen bevorzugte Version hinweisen.
Der Tag weist doppelte Inhalte als solche aus. Es kann auf einer einzelnen Domain oder auch domainübergreifend agieren. Eine Startseite beispielsweise sollte nicht über mehrere URLs erreichbar sein. Bei manchen ist dies jedoch der Fall, weil sie mit und ohne index.html geführt werden. Auf die index.html Seite kann in diesem Fall ein Tag gesetzt werden, der als Umleitung auf die richtige URL dient. Diese Umleitung wird im Quellcode einer Webseite eingefügt und verweist auf die ursprüngliche Quelle des Inhalts der Seite. Suchmaschinen wissen so, welche URL bevorzugt und ausgespielt werden soll.
Wenn Sie eine URL als kanonische Seite festlegen wollen, haben Sie laut Google Search Central mehrere Möglichkeiten:
rel="canonical"-link-Tag:
Sie können einen <link> -Tag im <head>-Abschnitt Ihres HTML-Codes verwenden, der kanonische Seiten festlegt.
Wenn Sie diese URL beispeielweise als kanonische URL verwenden wollen:
https://beispieldomain.de/kategorie/produkt
geben Sie diese so an:
Die duplizierten Seiten mit einem rel="canonical"-Link-Tag kennzeichen. Im <head>-Abschnitt der duplizierten Seiten ein <link>-Element mit Attribut rel="canonical" hinzufügen, dieses verweist auf die kanonische Seite:
Bei einer mobilen Version der kanonische Seite können Sie dieser einen
rel="alternate"-link hinzufügen, der dann auf die mobile Version der Seite weiterleitet:
Sie sollten darauf achten, dass bei dem rel="canonical"-link-Tag absolute statt relative Pfade angegeben werden, um die vollständige Position der Datei anzugeben:
HTTP-Header rel="canonical"
Wenn Sie Ihren Server konfigurieren können, haben Sie die Möglichkeit, anstelle eines Tags einen rel="canonical"-HTTP-Header zu verwenden, um die kanonische URL anzugeben.
Sie geben hier rel="canonical"-HTTP-Header für die duplizierten URLs aus, um aufzuzeigen, was die kanonische URL ist.
Sitemap
Eine Sitemap ist eine Datei, in der Sie Angaben zu URLs und anderen Dateien auf Ihrer Website machen können und Zusammenhänge zwischen diesen angeben. Suchmaschinen lesen dann diese Datei aus, um Ihre Website effizienter crawlen zu können.
Wählen Sie für jede der Webseiten eine kanonische URL aus und reichen Sie diese dann in einer Sitemap ein. Alle Seiten, die Sie in einer Sitemap aufführen, werden als kanonisch vorgeschlagen.Es sollten hier also keine Seiten hinzugefügt werden, die nicht kanonisch sind.
Sorgen Sie dafür, dass Ihre User zur richtigen Seite weitergeleitet werden, wenn Sie Ihre Website neu strukturiert haben. Die relevante Seite wird nach Umstrukturierungen durch den HTTP-Statuscode 301, eine Weiterleitung in der .htaccess Datei, dauerhaft an einen neuen Speicherort verschoben. Eine Weiterleitung ist ebenfalls dann sinnvoll, wenn Domains mit und ohne www, http, oder https aufrufbar sind. Durch die .htaccess-Datei legen Sie fest, dass die Domain ohne www auf die Domain mit www weitergeleitet wird.
Weiterleitung von Domain ohne www auf eine mit www oder umgekehrt:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^www.beispieldomain.de
RewriteRule ^(.*)$ http://besipieldomain.de$1 [R=301,L]
Eine dauerhafte Umleitung einer nicht mehr existenten Domain auf eine neue erreichen Sie über eine serverseitige Weiterleitung mit 301 Redirect per .htaccess Datei. Die User werden so auf das neue Ziel weitergeleitet:
noindex ist ein Attribut, welches im HTML-Code einer Website verwendet wird. Durch diesen Hinweis wird dem Google Crawler mitgeteilt, dass die URL nicht in den Suchmaschinenindex aufgenommen werden soll. Dieser Eintrag in die Metadaten ist besonders für URLs wichtig, die keinen oder nur wenig relevanten Content enthalten (beispielsweise Platzhalterseiten). Er verhindert, dass Seiten indexiert werden, die ähnliche Inhalte wie indexierte Seiten oder gar Doppelungen enthalten, wodurch Sie Duplicate Content effektiv vermeiden.
Für die Umsetzung des noindex-Hinweises in den HTML-Code bestehen zwei Möglichkeiten:
HTTP-Antwortheader:
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Dieses Link-Attribut kennzeichnet die jeweilige geographische Ausrichtung Ihrer Website. Wenn Inhalte für verschiedene Länder identisch sind und sich nicht in der Sprache unterscheiden, kann Duplicate Content entstehen. Hierbei hilft das HTML Meta-Element: Google spielt jeweils die regionale URL des Inhaltes in den Suchergebnissen aus.
Es gibt drei Möglichkeiten, dieses Link-Attribut anzugeben:
Hier können Sie im Header Ihrer Seite
<link rel="alternate" hreflang="lang_code" href="url_of_page" />
hinzufügen. Dadurch wird Google über alle Sprach-/ Regionsversionen einer Seite informiert. lang_code ist hierbei der Sprach- oder Regionscode, für den diese Version der Webseite ausgerichtet ist.
Durch einen HTTP-Header können Sie Google mit einer GET-Antwort darüber informieren, um welche Sprachversion es sich handelt. Diese Methode ist nützlich für Dateien wie PDFs.
<url_x>; rel="alternate"; hreflang="lang_code_x"
Auch durch eine Sitemap können Sie Google über die Sprach- und Regionsvarianten einer URL informieren.
Dafür fügen Sie ein <loc>-Element hinzu:
<loc>https://www.beispieldomain.com/english/page.html</loc>
In diesem <loc>-Element führen Sie jede einzelne URL mit untergeordneten <xhtml:link>-Einträgen auf.
In diesem Element sind jede Variante der Seite und die Seite selbst aufgeführt:
Sitemap:
<xhtml:link
rel="alternate"
hreflang="de"
href="https://www.beispieldomain.de/deutsch/page.html"/>
<xhtml:link
rel="alternate"
hreflang="en"
href="https://www.beispieldomain.com/english/page.html"/>
Wenn Sie die für Mobilgeräte optimierten Inhalte als zusätzliche URL betreiben, können Sie diese als Subdomain, in einem Unterverzeichnis der Hauptdomain oder als eigene Domain bereitstellen.
Google erkennt nicht automatisch, dass es sich um eine mobile Version einer Website handelt. Dies kann als Duplicate Content wahrgenommen werden. Um dies zu umgehen, können bei der Desktop Seite die <link> Elemente rel=“canonical” und rel=“alternate” mit Hinweis auf die mobile Version eingebaut werden.
Damit stellen Sie die Beziehung zwischen den zwei URLs dar:
Sie können diese Veränderungen im HTML-Code oder in der Sitemap eingeben.
Um diese Anmerkung im HTML-Code vorzunehmen, fügen Sie auf der Desktop-Seite dies hinzu:
Desktop-Version:
<link rel="alternate" media="only screen and (max-width: 640px)"
href="http://m.beispieldomain.com">
Auf der mobilen Seite fügen Sie hinzu:
Mobile Version:
<link rel="canonical" href="http://www.beispieldomain.com">
In der Sitemap können Sie folgenderweise auf eine mobile Version der Seite verweisen:
Sitemap:
<url>
<loc>http://www.beispieldomain.com</loc>
<xhtml:link rel="alternate" media="only screen and (max-width: 640px)"
href="http://m.beispieldomain.com" />
</url>
Durch einen Umstieg auf ein Content Management System können Sie eine Website mit einem mobilen responsiven Layout betreiben. Dieses passt sich optimal an das jeweilige Endgerät an.
Um Duplicate Content innerhalb von Shops zu vermeiden, können Sie die Seiten paginieren, die nur wenig weiteren Mehrwert zur Seite 1 einer Kategorie geben. Um hier gezielt Probleme zu vermeiden, können Sie mit den Link-Atributen rel="next" und rel="prev" arbeiten. Diese eignen sich, um die Beziehung zwischen einer Hauptkategorieseite und den Paginationsseiten für Google hervorzuheben.
Diese Elemente werden in den <head>-Abschnitt Ihrer HTML-Seite implementiert:
Für die http://www.beispieldomain.com/kategorie/page/3/ wären im HTML Head Bereich diese Angaben notwendig:
Angaben im HTML-Head Bereich:
<link rel="prev" href="http://www.beispieldomain.com/kategorie/page/2/" />
<link rel="next" href="http://www.beispieldomain.com/kategorie/page/4/" />
Diese Methode ist allerdings veraltet. Es ist stattdessen möglich, einen Canonical Tag auf der ersten Seite zu setzen oder die "View-All"-Methode zu verwenden, die auf einer Seite alle Produkte angezeigt. Hier verweisen einzelne Seiten per Canonical-Tag auf die erste Seite:
<link rel=“canonical“ href=“http://www.beispieldomain.com/kategorie/view-all/“>
Zitate oder zitierte Textpassagen werden durch Google nicht als Duplicate Content gewertet und nicht mit einer Google Penalty bestraft. Ausgenommen ist unsachgemässer Gebrauch, wie zum Beispiel das Zitieren einer ganzen Seite. Google legt besonders Wert darauf, dass dem User mit einer Seite ein zusätzlicher Mehrwert geboten wird. Ausserhalb des Zitates müssen also noch zusätzliche Informationen geboten werden, die anders aufgearbeitet sind, als auf der zitierten Seite. Infografiken oder andere Medien-Elemente sind hier eine beliebte Methode.
Wir müssen dennoch festhalten, dass Google die Originalquelle, also die von Ihnen zitierte Seite immer Ihrer zitierenden Seite vorziehen wird. Grund dafür ist, dass die Originalquelle bereits länger besteht und somit früher gecrawlt wurde als Ihre Quelle. Sie erhält dadurch eine Art “Vorreiter Status”.
Zitate müssen im Quellcode entsprechend gekennzeichnet werden:
Zitate im Quellcode:
<blockquote>Hier den zitierten Text einfügen - <cite>Hier Name des Autors oder die Quelle einfügen</cite></blockquote>
Gleiche Produktbeschreibungen auf unterschiedlichen Portalen wertet Google als Duplicate Content. Viele Online-Shops nutzen zum Verkauf jedoch nicht nur die eigene Domain, sondern verkaufen auch auf eBay, Amazon oder ähnlichen Portalen. Die bei Amazon verwendeten Produktbeschreibungen werden dabei häufig vom Hersteller zur Verfügung gestellt. Sie können aber in vielen verschiedenen Online Shops verwendet werden. Die Texte sind also nicht einzigartig, sondern finden sich auf vielen Webseiten.

Aber nicht nur über Händler riskieren Sie doppelte Inhalte. Auch Produktvergleichsseiten können zum Problem werden. Hier ist Ihre Kreativität gefragt, denn nur durch individuelle Produktbeschreibungen lässt sich dieses Problem lösen. Andernfalls riskieren Sie es, schlechter zu ranken und Kunden einzubüssen.
Die einfache Lösung zur Vermeidung von doppeltem Content ist das Verfassen von einzigartigen Produktbeschreibungen. Viele Shops nutzen für Produkte lediglich Standardtexte, die in der Regel vom Hersteller vorformuliert sind. Das Problem an diesen einfach zu implementierenden und ansprechend formulierten Texten ist aber, dass genau dieser Produkttext auf zahlreichen anderen Domains zu finden ist. Das ist nachvollziehbar, schliesslich werden viele Händler vom gleichen Hersteller beliefert und nutzen somit denselben Text für ihren Online-Shop. Mit einzigartigen Produkttexten haben Sie aber die Möglichkeit, sich von der Masse abzugrenzen und neue Kunden für sich zu gewinnen.
Soziale Medien tragen nicht direkt zu Suchmaschinen-Rankings bei, können aber dennoch Einfluss auf Ihren Status bei Google haben. Die Inhalte auf Social Media Plattformen wie Instagram, LinkedIn oder Facebook werden zwar anders indexiert als Web-Inhalte, werden aber dennoch positiv bewertet, wenn sie einzigartig formuliert oder aufgearbeitet werden. Gerade Social Media Plattformen bieten sich für unterschiedliche Content-Formate an, um Interaktion zu ermöglichen und das Interesse Ihrer Kunden zu wecken.

Wenn Sie Inhalte auf Ihrer Facebookseite oder auf anderen Social Media Kanälen teilen, sollten Sie die konkreten Inhalte nicht einfach kopieren, denn das sähe Google als Duplicate Content. Stattdessen empfehlen wir, Links zu Ihrer Website zu setzen und eigene Worte als Kommentare beizufügen.
Duplicate Content kann vor allem im Bereich SEO negative Auswirkungen haben und Optimierungsmassnahmen hemmen. So können zum Beispiel Rankings behindert werden, was zur Folge hat, dass der gewünschte Traffic auf Ihrer Website ausbleibt und so auch Ihr Gewinn stagniert. Der beste Weg, um Duplicate Content und seine Folgen zu umgehen, ist stets einzigartige und ansprechende Inhalte zu bieten, die nur auf Ihrer Webseite zu finden sind. Vermeiden Sie es, Inhalte von anderen Sites zu kopieren und setzen Sie stattdessen auf eigene und einzigartige Inhalte, um sich optimal zu präsentieren.
Verschiedene Tools ermöglichen es Ihnen, Ihre eigenen Inhalte auf doppelten Content hin zu überprüfen und gegebenenfalls zu überarbeiten. Dazu zählen zum Beispiel Sistrix oder Copyscape.
Auch auf der eigenen Seite gilt es, doppelten Content zu vermeiden. Durch verschiedene Filtereinstellungen oder Kategorien kann es vorkommen, dass Sie Ihre eigenen Inhalte mehrfach zur Verfügung stellen, was Google als doppelten Content werten kann, wenn Sie keine technischen Anpassungen vornehmen. Meist reichen kleine Anpassungen aus, um sicherzugehen, dass doppelte Seiten nicht indexiert werden und Ihnen so auch keine Probleme machen.
Wollen Sie sich viel Arbeit ersparen, geben Sie diese Aufgaben Experten wie uns in die Hand. Wir erstellen einzigartige Inhalte für Ihr Unternehmen und sorgen so dafür, dass Ihre Webseite bestmöglich rankt und stetig neue Besucher anzieht.
Wir von seonicals® unterstützen Sie bei der On- & Offpage-Optimierung Ihrer Website und erarbeiten mit Ihnen gemeinsam nachhaltige Strategien, um Ihrem Unternehmen langfristig zum Erfolg zu verhelfen. Kontaktieren Sie uns noch heute für ein kostenloses und unverbindliches Beratungsgespräch und erfahren Sie, was für Ihr Unternehmen alles möglich ist!
Wenn gleiche Inhalte auf unterschiedlichen URLs von Google gefunden werden, spricht man von Duplicate Content. Dies gilt für Webseiten der gleichen Domain (interner Duplicate Content), sowie für Webseiten mit unterschiedlichen Domains (externer Duplicate Content).
Duplicate Content kann sich negativ auf das Ranking Ihrer Website auswirken: Wenn Google während des Suchvorgangs Duplicate Content identifiziert und herausfiltert, erreichen diese Beiträge nämlich schlechtere oder gar keine Rankings. Der Sichtbarkeitsindex Ihrer Website kann so einbrechen oder verschlechtert sich deutlich. In den meisten Fällen bestraft Google doppelte Inhalte, aber nicht mit einer solchen Penalty.
Doppelte Inhalte können beispielsweise durch Kategorisierung und gleiche Produktbeschreibungen in Online-Shops entstehen, ebenso durch verschiedene Länderversionen einer Website oder durch Plagiate. Doppelungen können ebenfalls durch verschiedene URLs auftreten, wenn sie beispielsweise auf verschiedene Endgeräte ausgerichtet sind. Eine häufige Ursache für doppelten Content ist auch, dass eine Website sowohl mit als auch ohne www erreichbar bzw. per http und https erreichbar ist.
Um Duplicate Content zu finden, können kostenlose Content-Check Analyse Tools verwendet werden. Beispiele dafür sind Content Checker wie Siteliner, Copyscape, Screaming Frog, Yoast und Sistrix.
Sandra Fuchs
Unsere Redaktionsleiterin findet jeden noch so kleinen Pixelfehler und bearbeitet einen Text lieber einmal mehr, als einen unperfekten Beitrag online zu stellen.

Teile diesen Artikel



Sie machen den ersten Schritt. Wir übernehmen den Rest.
In einem persönlichen Gespräch lernen wir uns kennen und besprechen den Status Quo. Wie gesund ist Ihr Baum gerade – und wo benötigt er weitere Pflege?
Wir präsentieren Ihnen gewinnbringende Handlungsempfehlungen, mit deren Hilfe wir Potenziale aufzeigen und nachhaltiges Wachstum garantieren. Wir sorgen dafür, dass Ihr Baum die richtige Pflege erhält, um so viele Früchte wie möglich tragen zu können.
Mit dem richtigen Marketing-Mix machen wir aus Ihrem Unternehmen einen ernstzunehmenden Konkurrenten und entwickeln Ihre Marke stetig weiter – selbstverständlich immer im engen Austausch mit Ihnen. Damit garantieren wir jedes Jahr aufs Neue eine reichhaltige Ernte für Sie.
Wir bieten Ihnen eine kostenfreie Beratung, vor Ort oder online, in der wir Ihre Online-Marketing-Strategie analysieren und passende Massnahmen für Ihren Erfolg identifizieren.

Adrian Sandmeier
Ansprechpartner Schweiz


